classSolution{ public String longestPalindrome(String s){ if(s.length() < 2) { return s; } int start = 0, end = 0; for(int i = 0; i < s.length(); i++) { int len1 = hanshu(s, i, i); int len2 = hanshu(s, i, i + 1); int len = Math.max(len1, len2); if(len > end - start + 1) { start = i - (len - 1) / 2; end = i + len / 2; } } return s.substring(start, end + 1); }
publicinthanshu(String s , int start, int end){ while(start >= 0 && end < s.length() && s.charAt(start) == s.charAt(end)) { --start; ++end; } return end - start - 1; } }
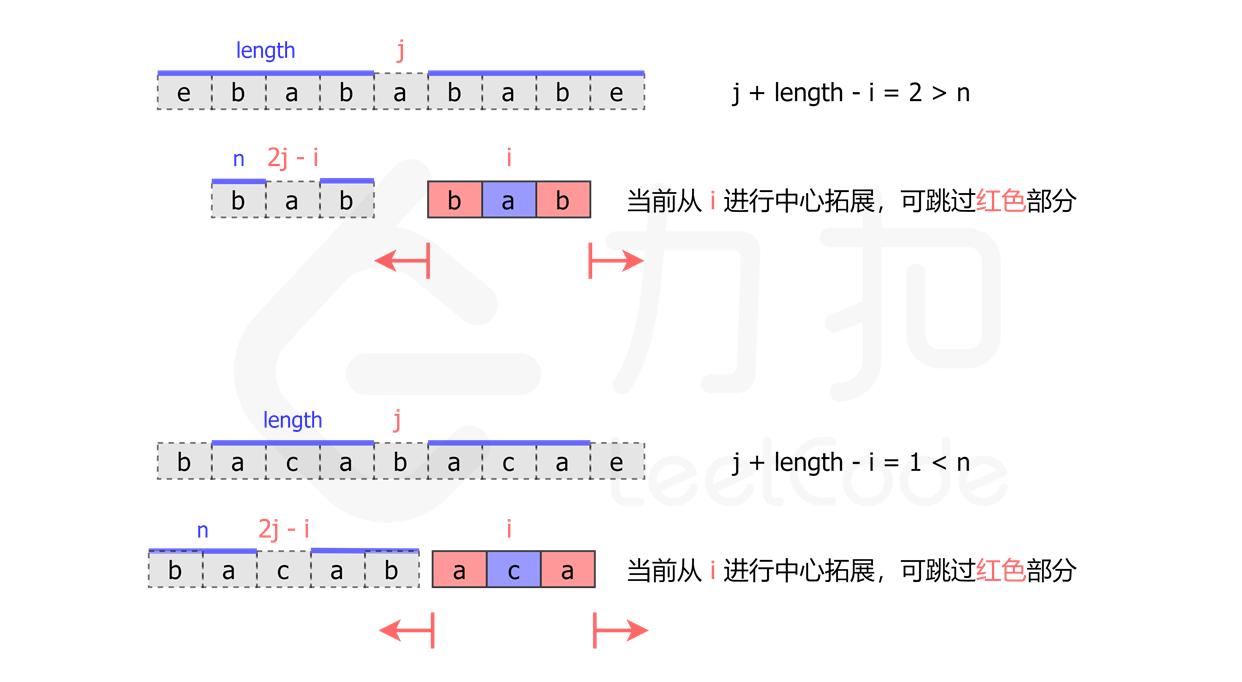
当在位置 i 开始进行中心拓展时,我们可以先找到 i 关于 j 的对称点 2 * j - i。那么如果点 2 * j - i 的臂长等于 n,我们就可以知道,点 i 的臂长至少为 min(j + length - i, n)。那么我们就可以直接跳过 i 到 i + min(j + length - i, n) 这部分,从 i + min(j + length - i, n) + 1 开始拓展。
class Solution { public: int expand(const string& s, int left, int right) { while (left >= 0 && right < s.size() && s[left] == s[right]) { --left; ++right; } return (right - left - 2) / 2; }
string longestPalindrome(string s) { int start = 0, end = -1; string t = "#"; for (char c: s) { t += c; t += '#'; } t += '#'; s = t;
vector<int> arm_len; int right = -1, j = -1; for (int i = 0; i < s.size(); ++i) { int cur_arm_len; if (right >= i) { int i_sym = j * 2 - i; int min_arm_len = min(arm_len[i_sym], right - i); cur_arm_len = expand(s, i - min_arm_len, i + min_arm_len); } else { cur_arm_len = expand(s, i, i); } arm_len.push_back(cur_arm_len); if (i + cur_arm_len > right) { j = i; right = i + cur_arm_len; } if (cur_arm_len * 2 + 1 > end - start) { start = i - cur_arm_len; end = i + cur_arm_len; } }
string ans; for (int i = start; i <= end; ++i) { if (s[i] != '#') { ans += s[i]; } } return ans; } };
classSolution{ public String longestPalindrome(String s){ StringBuffer sb = new StringBuffer("#"); for(int i = 0; i < s.length(); i++) { sb.append(s.charAt(i)); sb.append('#'); } s = sb.toString();
List<Integer> arm_len = new ArrayList<Integer>(); int start = 0, end = -1, right = -1, j = -1; for(int i = 0; i < s.length(); i++) { int len; if(right >= i) { int i0 = j * 2 - i; int min = Math.min(arm_len.get(i0), right - i); len = hanshu(s, i - min, i + min); } else { len = hanshu(s, i, i); } arm_len.add(len); if(i + len > right) { j = i; right = i + len; } if(len * 2 + 1 > end - start) { start = i - len; end = i + len; } }
StringBuffer sb0 = new StringBuffer(); for(int i = start; i <= end; i++) { if(s.charAt(i) != '#') { sb0.append(s.charAt(i)); } }
return sb0.toString(); }
publicinthanshu(String s , int start, int end){ while(start >= 0 && end < s.length() && s.charAt(start) == s.charAt(end)) { --start; ++end; } return (end - start - 2) / 2; } }